Recent decades have seen an explosion of interest in moving beyond the traditional pre-publication peer review model – along with its many documented problems (e.g., see Brembs, 2019) – and toward a post-publication peer review / open evaluation (OE) model that would leverage the internet to increase the speed, reliability and efficiency of scholarly publishing (Tennant, 2018; Kriegeskorte, 2012; Yarkoni, 2012 etc.). Despite the emergence of numerous OE journals (e.g., F1000) and platforms (e.g., PREreview), however, community support for such systems remains low. Here, I argue that the principle reason for this low rate of uptake is not a lack of desire in the community, but because these platforms fail to tap into the self-reinforcing cycle that maintains the traditional journal hierarchy. Specifically, researchers are typically rewarded (e.g., via hiring and promotion procedures) according to the ‘prestige’ of the journal in which they publish their work. Since prestige is typically taken to be synonymous with the journal impact factor (JIF), researchers have a powerful incentive to publish their best work in highly-selective journals that prioritise impactful qualities (e.g., novelty) for publication, rather than their less- or non-selective OE counterparts. Although many OE models attempt to incentivise high-quality contributions through the use of article-level metrics, these metrics can only incentivise behaviour to the degree that they are adopted and recognised by the research community and evaluative stakeholders (e.g., universities, funders). Thus, the global research community is trapped in a collective action problem: the widespread adoption of the OE model and assocated article-level metrics could benefit the entire community, but these systems remain underutilised due to conflicting interests at the individual level, which instead maintain the traditional journal hierarchy and associated journal-level metrics (e.g., JIF).
Here and in the following series of posts, I’ll propose a novel OE model that specifically aims to tackle this ‘prestige problem’ by developing prestige at the journal level. This proposal should thus be considered as a ‘stepping stone’ between the current impact-based journal paradigm and some future paradigm, in which journals no longer exist and articles are evaluated on their own individual merits. Consistent with previous models, my proposal states that: (1) articles are first published as preprints; (2) articles passing some minimum level of rigour (perhaps decided by an academic editor) are then evaluated by several reviewers, who provide both qualitative reviews and numerical ratings on multiple qualities of interest (e.g., novelty, reliability; for a full exposition of this idea, see Kriegeskorte, 2012), and (3) review reports are themselves reviewed and rated on various qualities of interest (e.g., constructiveness). Steps 2 and 3 could occur iteratively, if authors wish to update their article in response to reviewers’ and editor’s reviews. The novel part of my proposal is in suggesting that algorithms should then be trained on these data to classify articles into different ‘tiers’ according to their perceived quality (e.g., high vs low) and/or predicted impact (more on this later). Since notions of quality and impact vary considerably between research fields, separate algorithms would need to be developed for each field of interest. To minimise friction with existing roles and processes, an early version of these ‘quality algorithms’ could reflect a simple linear combination of reviewers’ ratings, weighted by an editor’s evaluation of each review. In essence, this prototype model would aim to capture and quantify the rich set of subjective evaluations that reviewers and editors make during the traditional peer review process, but are typically reduced to a unidimensional, binary outcome (i.e., reject/accept) and/or sequestered for the publisher’s exclusive use. Future versions of the model could include additional signals of interest (e.g., reviewer reputation scores; Yarkoni, 2012) following their support by the community in question and validation through meta-research (research on research). Crucially, each tier of articles would then be published under a different journal title reflecting its level of quality/impact (e.g., “Anti-journal of Psychology: Alpha”, “Anti-journal of Psychology: Beta”). Over time, the upper tier/s in this system should begin to attract more citations – and associated ‘prestige’ (via the JIF) – than the lower tiers, which should then incentivise more high-quality contributions. This strategy is designed tap into the two key mechanisms thought to underlie the ‘self-fulfilling prophecy of journal prestige’ (see Figure 2 below, taken from Kriegeskorte, 2012):
- The virtuous cycle: articles in the upper tiers should be of higher quality than those in the lower tiers (providing we can trust our community and algorithms to evaluate quality)
- The vicious cycle: articles in the upper tiers will be perceived as being of higher quality than those in the lower tiers, thus enticing more attention and citations
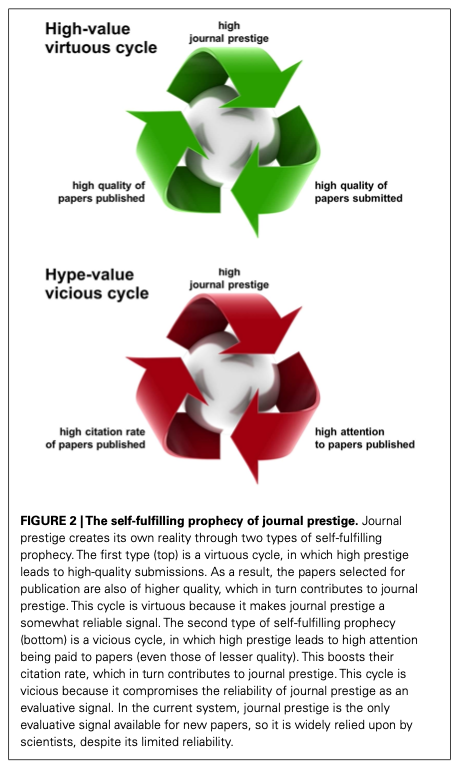
Note that the goal of this model is not simply to replicate the traditional journal hierarchy, but to incentivise contributions (articles, reviews, editorial services) from prestige-motivated researchers, who can begin to collectively accumulate a rich dataset of article-level ratings on various metrics. As support for the model grows, it could then begin to evolve in line with the needs of the community and the principles of science itself. For example, meta-researchers could explore ways to optimise the metrics, or develop algorithms to predict other important – but currently neglected – qualities of interest (e.g., replicability), gradually shifting the focus away from impact as the de facto heuristic for quality in academia. Following a sufficient level of community adoption, the journal partitions could be dropped altogether, allowing the transition to a flexible suite of algorithms that serve different users according to their individual needs. In this way, the model I propose could be viewed as a ‘trojan horse’, with which the research community can smuggle in a range of powerful new article-level metrics, under the guise of a more traditional journal. The model that I propose would be open, cheap, fast, scalable, dynamic, crowdsourced, open source, evidence-based, flexible, precise, and profitable (more on these features later). Most importantly, because the model guarantees that all research above some minimum level of rigour will be published, researchers could get on with what they want to do the most – namely, conducting research, rather than jumping through hoops to get their research published.
We recently took what could be a first step toward achieving this vision, by founding Project MERITS at the eLife Innovation Sprint, which could potentially evolve into the rich evaluation dataset I described above. In the following series of posts, I’ll provide more detail on the current scholarly publishing system, share more details of my proposed model and outline a tractable plan for bringing it into fruition. I’ll also propose a radically new, decentralised economic model for academia, which I think could eventually foster the type of reliability-based internet system I’ve described previously. As always, keen for any feedback or critique you may have on these ideas.
Thanks for reading! Let me know if you have any feedback in the comments below and please subscribe by clicking the paper aeroplane icon below. My next blog post will describe the traditional publishing system and what I call the ‘prestige problem’ in academia. Thank you to Megan Campbell, Alex Holcombe, Brian Nosek, Claire Bradley and Jon Tennant for helpful comments on an earlier version of the manuscript this abstract is taken from, plus all of the countless researchers who offered feedback on these ideas over the past few years.